There are few applications created in today’s world that achieve scalability and/or profitability without thoughtful reporting. The key is to be able to push a massive number of tiny, discrete events, and to both aggregate them and view them in near real-time. This allows you to identify bottlenecks and trends.
This is where the statsd project (by etsy) and the Graphite project (originally by Orbitz) comes in. A statsd client allows you to push and forget as many events as you’d like to the statsd server (using UDP, which is connectionless, but aggressive). The statsd server pushes them to Carbon (the storage backend for Graphite). Carbon stores to a bunch of Whisper-format files.
When you wish to actually watch, inspect, or export the graphs, you’ll use the Graphite frontend/dashboard. The frontend will establish a TCP connection to the backend in order to read the data. The Graphite frontend is where the analytical magic happens. You can have a bunch of concurrent charts automatically refreshing. Graphite is simply a pluggable backend (and, in fact, the default backend) of statsd. You can use another, if you’d like.
The purpose of this post is to not necessary spread happiness or usage examples about statsd/Graphite. There’s enough of that. However, as painful as the suite is to set-up in production, it’s equally difficult just to freaking get it running just for development. The good news is that there is an enormous following and community for the components, and that they are popular and well-used. The bad news is that issues and pull-requests for Graphite seems to be completely ignored by the maintainers. Worse, there are almost no complete or accurate examples of how to install statsd, Carbon, and Graphite. It can be very discouraging for people that just want to see how it works. I’m here to help.
These instructions work for both Ubuntu 13.10 and 14.04, and OS X Mavericks using Homebrew.
Installing Graphite and Carbon
Install a compatible version of Django (or else you’ll see the ‘daemonize’ error, if not others):
$ sudo pip install Django==1.4 graphite-web carbon
This won’t install some/all of the dependencies. Finish-up by installing a dependency for Graphite:
$ sudo apt-get install libcairo-dev
If you’re using Homebrew, install the “cairo” package.
Finish-up the dependencies by installing with the requirements file:
$ sudo pip install -r https://raw.githubusercontent.com/graphite-project/graphite-web/master/requirements.txt
If you’re running on OS X and get an error regarding “xcb-shm” and “cairo”, you’ll have to make sure the pkgconfig script for xcb-shm is in scope, as it appears to be preinstalled with OS X in an unconventional location:
$ PKG_CONFIG_PATH=/opt/X11/lib/pkgconfig pip install -r https://raw.githubusercontent.com/graphite-project/graphite-web/master/requirements.txt
It’s super important to mention that graphite only works with Twisted 11.1.0 . Though the requirements will install this, any other existing version of Twisted will remain installed, and may preempt the version that we actually require. Either clean-out any other versions beforehand, or use a virtualenv.
Configure your installation:
$ cd /opt/graphite
$ sudo chown -R dustin.dustin storage
$ PYTHONPATH=/opt/graphite/webapp django-admin.py syncdb --settings=graphite.settings
Answer “yes” when asked if you should create a superuser, and provide credentials.
Use default configurations:
$ sudo cp conf/carbon.conf.example conf/carbon.conf
$ sudo cp conf/storage-schemas.conf.example conf/storage-schemas.conf
$ sudo cp webapp/graphite/local_settings.py.example webapp/graphite/local_settings.py
Edit webapp/graphite/settings.py and set “SECRET_KEY” to a random string:
Make sure “WHISPER_FALLOCATE_CREATE” is set to “False” in conf/carbon.conf .
Start Carbon:
$ bin/carbon-cache.py start
/usr/lib/python2.7/dist-packages/zope/__init__.py:3: UserWarning: Module twisted was already imported from /usr/local/lib/python2.7/dist-packages/twisted/__init__.pyc, but /opt/graphite/lib is being added to sys.path
import pkg_resources
Starting carbon-cache (instance a)
Start Graphite with development-server script:
$ bin/run-graphite-devel-server.py /opt/graphite
Running Graphite from /opt/graphite under django development server
/usr/local/bin/django-admin.py runserver --pythonpath /opt/graphite/webapp --settings graphite.settings 0.0.0.0:8080
Validating models...
0 errors found
Django version 1.4, using settings 'graphite.settings'
Development server is running at http://0.0.0.0:8080/
Quit the server with CONTROL-C.
No handlers could be found for logger "cache"
[03/May/2014 16:23:48] "GET /render/?width=586&height=308&_salt=1399152226.921&target=stats.dustin-1457&yMax=100&from=-2minutes HTTP/1.1" 200 1053
Obviously this script is not meant for the production use of Django, but it’ll be fine for development. You can open the Graphite dashboard at:
http://localhost:8080/
Since the development server binds on all interfaces, you can access it from a non-local system as well.
Installing statsd
Install node.js:
$ sudo apt-get install nodejs
If you’re using Brew, install the “node” package.
We’ll put it in /opt just so that it’s next to Graphite:
$ cd /opt
$ sudo git clone https://github.com/etsy/statsd.git
$ cd statsd
$ sudo cp exampleConfig.js config.js
Update “graphiteHost” in config.js, and set it to “localhost”.
If you want to get some verbosity from statsd (to debug the flow, if needed), add “debug” or “dumpMessages” with a boolean value of “true” to config.js.
To run statsd:
$ node stats.js config.js
17 Jul 22:31:25 - reading config file: config.js
17 Jul 22:31:25 - server is up
Using the statsd Python Client
$ sudo pip install statsd
Sample Python script:
import time
import random
import statsd
counter_name = 'your.test.counter'
wait_s = 1
while 1:
c = statsd.StatsClient('localhost', 8125)
random_count = random.randrange(1, 100)
print("Count=(%d)" % (random_count))
while random_count > 0:
c.incr(counter_name)
random_count -= 1
time.sleep(wait_s)
This script will post a random number of events in clustered bursts, waiting for one second in between.
Using Graphite
Graphite is a dashboard that allows you to monitor many different charts simultaneously. Any of your events will immediately become available from the dashboard, though you’ll have to refresh it to reflect new ones.
When you first open the dashboard, there will be a tree on the left that represent all of the available events/metrics. These not only include the events that you sent, but statistics from Carbon and statsd, as well.
The chart representing the script above can be found under:
Graphite -> stats_counts -> your -> test -> counter
The default representation of the chart probably won’t usually make much sense. Change the following parameters:
-
Click the “Graph Options” button (on the graph), click “Y-Axis” -> “Maximum”, and then set it to “100”.
-
Click on the third button from the left at the top of the graph to view a tighter time period. Enter ten-minutes.
By default, you’ll have to manually press the button to update (the left-most one, at the top of the graph). There’s an “Auto-Refresh” button that can be clicked to activate an auto-refresh, as well.
If at some point you find that you’ve introduced data that you’d like to remove, stop statsd, stop Graphite, stop Carbon, identify the right Whisper file under /opt/graphite/storage/whisper and delete it, then start Carbon, start Graphite, and start statsd.
Using Nginx and Gunicorn
As if the difficulty of getting everything else working isn’t enough, Django is broken by default. It actually seems to depend on the gunicorn_django boot script, which is now obsolete.
Getting Graphite working hinges on the WSGI interface being available for Gunicorn.
You need to copy /opt/graphite/conf/graphite.wsgi.example to /opt/graphite/webapp/graphite, but you’ll need to name it so that it’s importable by Gunicorn (no periods exception for the extension). I call mine wsgi.py. You’ll also have to refactor how it establishes the application object.
This is the original two statements:
import django.core.handlers.wsgi
application = django.core.handlers.wsgi.WSGIHandler()
You’ll need to replace those two lines with:
from django.core.wsgi import get_wsgi_application
application = get_wsgi_application()
This should be the contents of your WSGI module, sans the commenting:
import os, sys
sys.path.append('/opt/graphite/webapp')
os.environ['DJANGO_SETTINGS_MODULE'] = 'graphite.settings'
from django.core.wsgi import get_wsgi_application
application = get_wsgi_application()
from graphite.logger import log
log.info("graphite.wsgi - pid %d - reloading search index" % os.getpid())
import graphite.metrics.search
From /opt/graphite/webapp/graphite, run the following:
$ sudo gunicorn -b unix:/tmp/graphite_test.gunicorn.sock wsgi:application
This is an example Nginx config, to get you going:
upstream graphite_app_server {
server unix:/tmp/graphite_test.gunicorn.sock fail_timeout=0;
}
server {
server_name graphite.local;
keepalive_timeout 5;
root /opt/graphite/webapp/graphite/content;
location /static/ {
try_files $uri 404;
}
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://graphite_app_server;
}
}
Troubleshooting
If you get the following, completely-opaque Gunicorn “Worker failed to boot” error, Google will only render a list of [probably] unrelated problems:
Traceback (most recent call last):
File "/usr/local/bin/gunicorn", line 9, in
load_entry_point('gunicorn==19.0.0', 'console_scripts', 'gunicorn')()
File "/Library/Python/2.7/site-packages/gunicorn/app/wsgiapp.py", line 74, in run
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
File "/Library/Python/2.7/site-packages/gunicorn/app/base.py", line 166, in run
super(Application, self).run()
File "/Library/Python/2.7/site-packages/gunicorn/app/base.py", line 71, in run
Arbiter(self).run()
File "/Library/Python/2.7/site-packages/gunicorn/arbiter.py", line 169, in run
self.manage_workers()
File "/Library/Python/2.7/site-packages/gunicorn/arbiter.py", line 477, in manage_workers
self.spawn_workers()
File "/Library/Python/2.7/site-packages/gunicorn/arbiter.py", line 537, in spawn_workers
time.sleep(0.1 * random.random())
File "/Library/Python/2.7/site-packages/gunicorn/arbiter.py", line 209, in handle_chld
self.reap_workers()
File "/Library/Python/2.7/site-packages/gunicorn/arbiter.py", line 459, in reap_workers
raise HaltServer(reason, self.WORKER_BOOT_ERROR)
gunicorn.errors.HaltServer: <HaltServer 'Worker failed to boot.' 3>
Technically, this probably means that just about anything could’ve gone wrong. However, If you forget to do the syncdb above or don’t replace those statements in the WSGI file, you’ll get this error. I’ll be happy if I can save you the time by mentioning it, here.
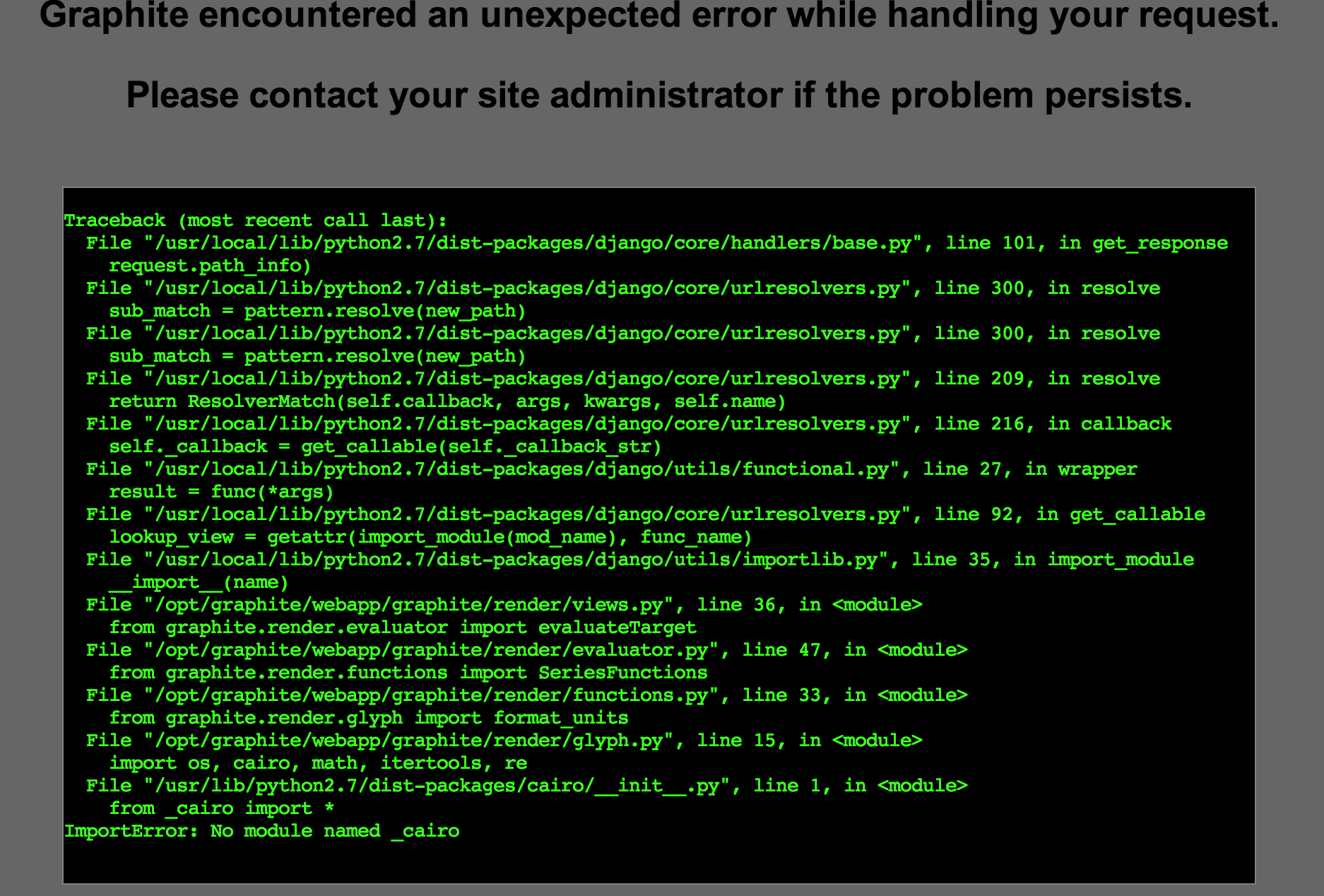
If you get a 500-error loading one or more dependencies for Graphite in the webpage, make sure debugging is turned-on in Gunicorn, and open that resource in another tab to see a stacktrace:

This particular error (“ImportError: No module named _cairo”) can be solved in Ubuntu by reinstalling a broken Python Cairo package:
$ sudo apt-get install --reinstall python-cairo
If you get Graphite running but aren’t receiving events, make sure that statsd is receiving the events from your client(s) by enabling its “dumpMessages” option in its config. If it is receiving the events, then check the /opt/graphite/storage/whisper directory. If there’s nothing in it (or it’s not further populating), then you have a file-permissions problem, somewhere (everything essentially needs to be running as the same user, and they all need access to that directory).


You must be logged in to post a comment.