
I’m trying to post metrics for the current balance. The balance in the current account is 513.66 . The suggestions I found online were variations of this with the same result:
$ aws ce get-cost-and-usage --time-period Start=2026-05-01,End=2026-06-01 --granularity MONTHLY --metrics "UnblendedCost" --query 'ResultsByTime[0].Total.UnblendedCost.Amount' --output text-0.0000001087
The response is typically 0.0, plus/minus some degree of tiny floating-point error.
Clicking on the amount in the Console…:
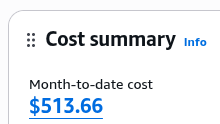
…will take you to the actual reporting screen:
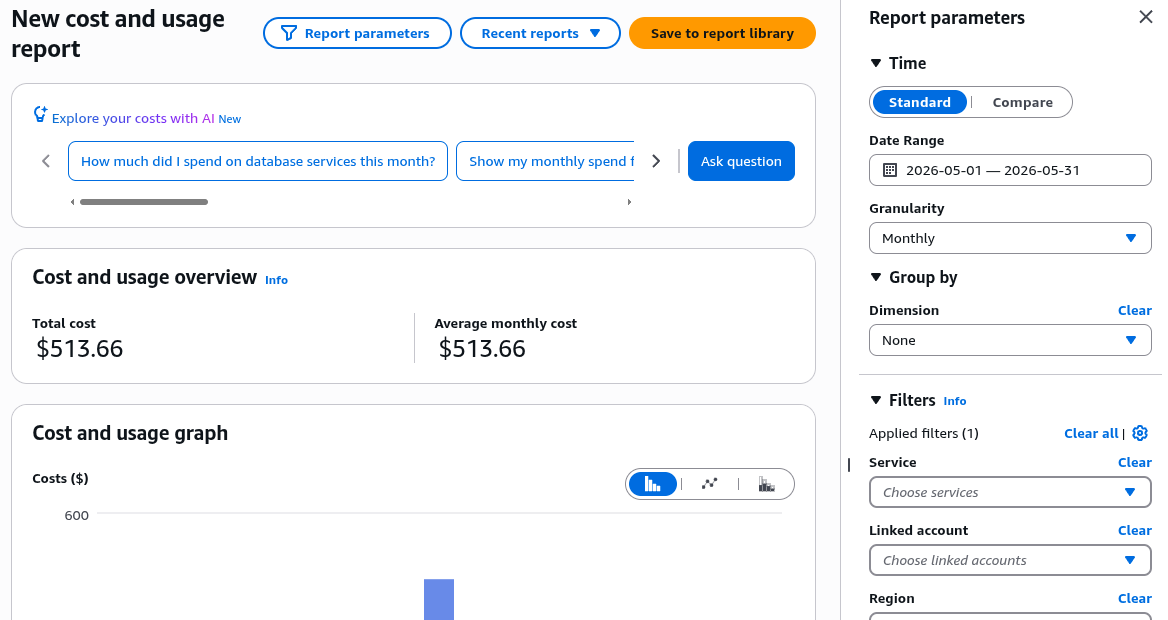
Looking at the filters, it shows that “(1)” was applied. Interesting. Expanding the extra filters at the bottom, it suddenly shows some excluded items under “Charge type”:
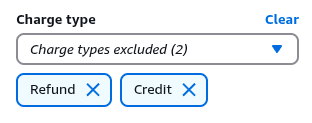
This ended-up being the culprit. It’s not clear how this influences the results since I also calculated month-to-date balance values for every day of the present month, and they were all near zero regardless. However, accounting for this at the CLI finally produced a matching balance (using the --filter parameter):
$ aws ce get-cost-and-usage --time-period Start=2026-05-01,End=2026-06-01 --granularity MONTHLY --metrics "UnblendedCost" --query 'ResultsByTime[0].Total.UnblendedCost.Amount' --output text --filter '{"Not":{"Dimensions":{"Key":"RECORD_TYPE","Values":["Credit","Refund"]}}}'513.6641476331
For completeness, this is the corresponding Python script for retrieving the same thing with Boto:
import boto3cost_explorer_client = boto3.client("ce")get_cost_and_usage_response = cost_explorer_client.get_cost_and_usage( TimePeriod={ "Start": "2026-05-01", "End": "2026-06-01", }, Granularity="MONTHLY", Metrics=["UnblendedCost"], Filter={ "Not": { "Dimensions": { "Key": "RECORD_TYPE", "Values": ["Credit", "Refund"], }, }, },)results_by_time_rows = get_cost_and_usage_response["ResultsByTime"]first_result_row = results_by_time_rows[0]total_block = first_result_row["Total"]unblended_cost_block = total_block["UnblendedCost"]print(unblended_cost_block["Amount"])

You must be logged in to post a comment.